Привіт усім.
Напевно усім, хто займається програмуванням, виникала необхідність отримувати певні файли з мережі Інтернет. Сьогодні ми розглянемо таку чудову вільно доступну бібліотеку-компонент libcurl, яка для цього і призначена.
Отримання і встановлення libcurl
А розпочнемо ми звичайно з того, де ж цю пречудову бібліотеку отримати? А отримати її можна з офіційного сайту, який знаходиться за посиланням http://curl.haxx.se/libcurl/. В ньому розміщена також документація по API даної бібліотеки, так-що не соромтесь, почитайте. Хто не знає, до-речі, вона написана на С. Сторінка завантаження виглядає наступним чином:
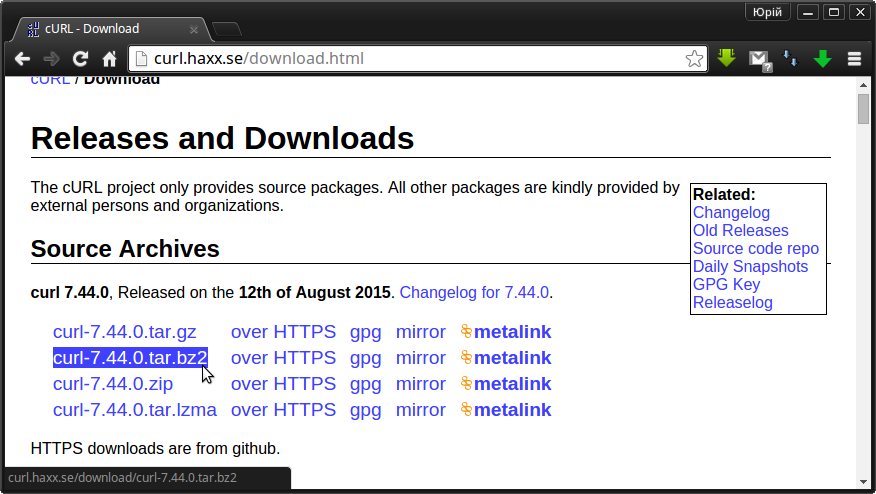 Завантажуємо останню версію в потрібному форматі архівів у вибрану директорію і розпаковуємо її за допомогою свого улюбленого архіватора (у мене це програма tar):
Завантажуємо останню версію в потрібному форматі архівів у вибрану директорію і розпаковуємо її за допомогою свого улюбленого архіватора (у мене це програма tar):
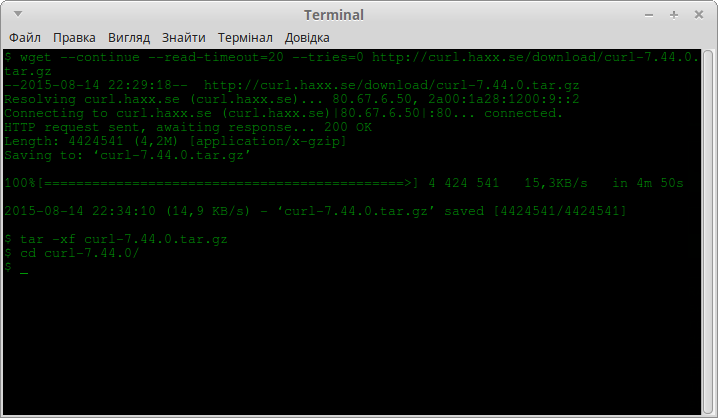 Тепер, в наших руках знаходиться ціле дерево вихідного коду усієї бібліотеки разом з програмою проекту curl. Для того, хто працює в Юнікс-подібному операційному середовищі, виконання наступних команд, будуте зовсім звичайним ділом.
Тепер, в наших руках знаходиться ціле дерево вихідного коду усієї бібліотеки разом з програмою проекту curl. Для того, хто працює в Юнікс-подібному операційному середовищі, виконання наступних команд, будуте зовсім звичайним ділом.
Компілювання в Юнікс-подібних ОС
Виконайте наступні команди командного інтерпретатора, для того щоб зібрати бібліотеку і програму curl (попередньо не забувши ввійти в кореневий каталог вихідного коду бібліотеки):
./configure && make
Команда “./configure” виконає усі необхідні підготування і перевірки для компіляції пакету, а команда “make” - виконає безпосередньо компілювання і компонування елементів бібліотеки. Оператор у вигляді двох амперсантів (“&&”) означає логічне “І”, тобто, якщо скрипт “configure” завершиться з помилкою, програма “make” не запуститься. Після виконання цих команд, можна виконати команду “make install”, яка встановить усі елементи пакету у відповідні директорії. Для більш точного налаштування пакету, виконайте скрипт “configure” з параметром “--help”:
./configure —help
Після чого на екрані з'являться додаткові параметри налаштування пакету.
Іншим шляхом встановлення пакету curl в Юнікс-подібних операційних системах являється використання менеджера пакетів на подобі “apt-get” (для ОС на базі Debian в тому числі і Ubuntu). Для встановлення файлів libcurl для розробників ПЗ, виконайте наступну команду:
sudo apt-get install libcurl4-openssl-dev
Після виконання даної команди, Ви можете отримати приблизно такий результат:
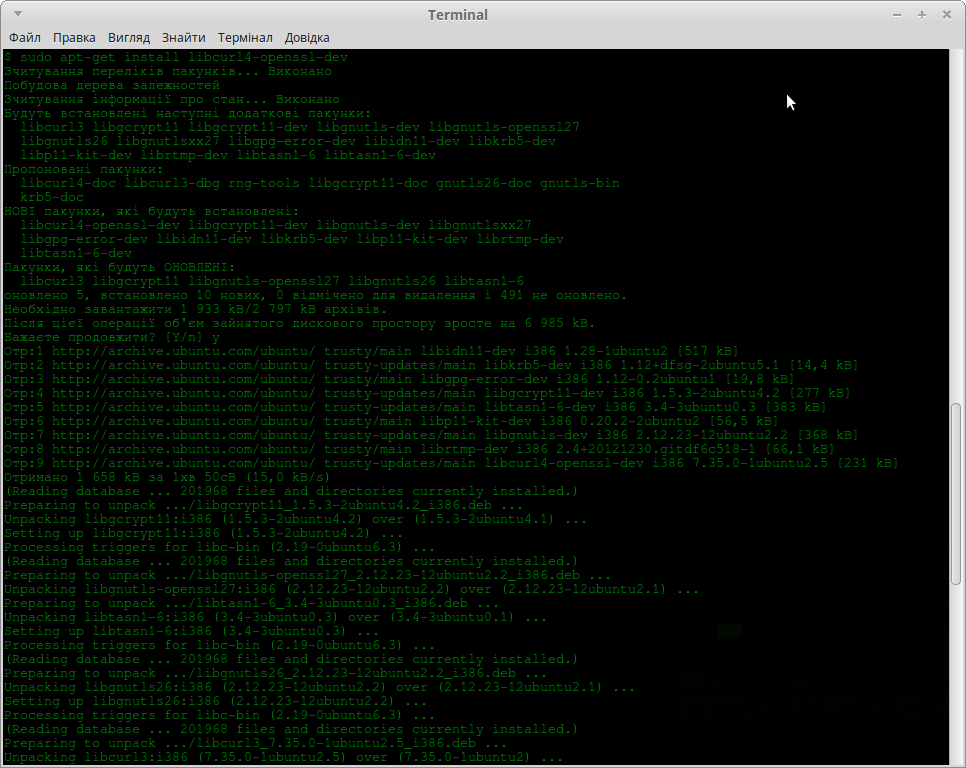 Тепер Ви готові використовувати libcurl у своїх програмах.
Тепер Ви готові використовувати libcurl у своїх програмах.
Збирання пакету на базі ОС сімейства Windows
Для безпосереднього збирання пакету libcurl на Вашому персональному комп'ютері, вам необхідно завантажити і встановити Windows SDK (Software Development Kit — інструментарій розробника) з офіційного сайту Miscrosoft, або ж встановити MinGW разом з портованим компілятором GCC. Тут ми розглянемо збирання пакету за допомогою Windows SDK, який Ви можете завантажити за адресою http://www.microsoft.com/en-us/download/details.aspx?id=8279 (SDK для Windows 7), або ж за допомогою іншого URL. Я ж буду використовувати Windows SDK старої версії для XP. У склад даного інструментарію розробника входиться програма “nmake” - аналог “make” у Юнікс-подібних системах, cl.exe — компілятор від Майкрософт, link.exe — компонувальник, rc.exe — система компіляції ресурсів. Для використання бібліотеки libcurl, нам також знадобиться бібліотека С-Runtime Library (“msvcr90.dll” для 9.0 версії SDK або іншої версії).
Отже, відкриваємо командний інтерпретатор від SDK (за шляхом: Пуск->Програми->Windows SDK->Shell) і за допомогою команди “cd” переходимо у корінь вихідного коду пакету libcurl. Після чого нам необхідно перейти у каталог winbuild, за допомогою цієї ж команди. Тепер, у нас є два варіанти: зібрати бібліотеку як статичну бібліотеку, або ж як динамічний програмний компонент. Як на мене, найкраще все-таки збирати бібліотеку як динамічний програмний компонент. Для цього необхідно ввести наступну команду:
nmake -f Makefile.vc -mode=dll
Командний рядок буде приблизно виглядати наступним чином:
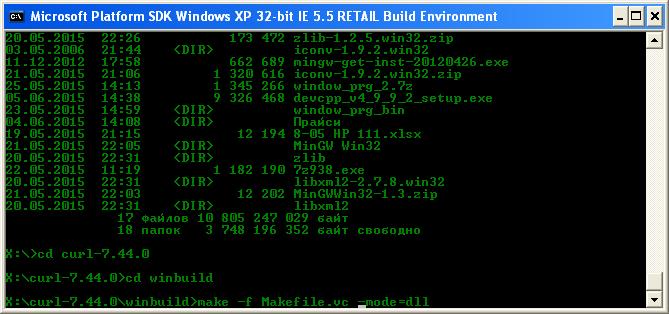 У мене кореневий каталог пакету знаходиться на диску X:\, а у старій версії Windows SDK програма “nmake” називається “make”. Якщо у Вас новіша версія SDK вводьте замість “make” “nmake”, або ж Ви не зможете зібрати пакет.
Після натискання клавіші “Enter”, у стандартний вивід буде надходити велика кількість інформації про поточні операції. В результаті успішної побудови, у кореневому каталозі пакету curl з'явиться каталог “builds” в підкаталогах якого будуть знаходитись необхідні нам файли “libcurl.dll” і “libcurl.lib”, які і необхідно скопіювати у директорію розміщення нашої майбутньої програми. Також необхідно скопіювати заголовкові файли разом з їхнім кореневим каталогом “curl”, які знаходяться приблизно за таким шляхом: “curl-7.42.0\builds\libcurl-vc9-x86-release-dll-ipv6-sspi-winssl\include\”. Вам необхідно скопіювати файли разом з каталогом “curl” у іншому випадку, Ви можете зіткнутись з проблемами компіляції Вашої програми.
У мене кореневий каталог пакету знаходиться на диску X:\, а у старій версії Windows SDK програма “nmake” називається “make”. Якщо у Вас новіша версія SDK вводьте замість “make” “nmake”, або ж Ви не зможете зібрати пакет.
Після натискання клавіші “Enter”, у стандартний вивід буде надходити велика кількість інформації про поточні операції. В результаті успішної побудови, у кореневому каталозі пакету curl з'явиться каталог “builds” в підкаталогах якого будуть знаходитись необхідні нам файли “libcurl.dll” і “libcurl.lib”, які і необхідно скопіювати у директорію розміщення нашої майбутньої програми. Також необхідно скопіювати заголовкові файли разом з їхнім кореневим каталогом “curl”, які знаходяться приблизно за таким шляхом: “curl-7.42.0\builds\libcurl-vc9-x86-release-dll-ipv6-sspi-winssl\include\”. Вам необхідно скопіювати файли разом з каталогом “curl” у іншому випадку, Ви можете зіткнутись з проблемами компіляції Вашої програми.
Компонування програми з бібліотекою libcurl
Для того щоб ми могли використовувати функції даної бібліотеки у своїй програмі, перш за все, необхідно її скомпонувати з нею.
У Юнікс-подібних системах, Вам необхідно передати компілятору параметри: -lcurl і не забути підключити заголовковий файл у свій вихідний код програми. Команда яка повністю компілює і компонує Вашу програму з вихідного коду, який знаходиться у файлі “main.cpp” виглядає наступним чином:
g++ -o test main.cpp -lcurl
Все, тепер ви можете повністю використовувати функціонал бібліотеки.
З Windows-машинами не все так гладко. Окрім самої бібліотеки “libcurl.dll” і файлу “libcurl.lib” нам також знадобиться бібліотека “msvcr90.dll” або ж “msvcr80.dll” в залежності від версії вашого SDK. А для того щоб використовувати дану бібліотеку від Майкрософт, в обов'язковому порядку нам знадобиться “manifest”-файл з приблизно наступним змістом:
<?xml version='1.0' encoding='UTF-8' standalone='yes'?>
<assembly xmlns='urn:schemas-microsoft-com:asm.v1' manifestVersion='1.0'>
<trustInfo xmlns="urn:schemas-microsoft-com:asm.v3">
<security>
<requestedPrivileges>
<requestedExecutionLevel level='asInvoker' uiAccess='false' />
</requestedPrivileges>
</security>
</trustInfo>
<dependency>
<dependentAssembly>
<assemblyIdentity type='win32' name='Microsoft.VC90.CRT' version='9.0.21022.8' processorArchitecture='x86' publicKeyToken='1fc8b3b9a1e18e3b' />
</dependentAssembly>
</dependency>
</assembly>
Без нього, бібліотека libcurl не зможе коректно завантажити у пам'ять компонент “msvcr90.dll”. Ми назвемо файл з цим вмістом, як “libcurl.manifest”. І повний список команд для побудови власних програм, виглядає наступним чином:
cl.exe -c main.cxx
link.exe main.obj libcurl.lib
mt.exe -manifest libcurl.manifest -outputresource:main.exe;1
Остання команда вбудовує manifest-файл у нашу програму.
Завантажуємо сторінку з інтернету
Тепер перейдемо власне до самого інтерфейсу бібліотеки і завантаження контенту з мережі Інтернет.
Спеціально для цього, розробники бібліотеки libcurl, створили два інтерфейси: “easy” - простий інтерфейс для одного завдання на завантаження; і інтерфейс “multi” - для асинхронного виконання завдань. Для початку, ми будемо використовувати інтерфейс “easy”.
Але спершу ніж використовувати саму бібліотеку, необхідно викликати дві важливі функції: curl_global_init() і curl_global_cleanup(). Перша з них ініціалізовує внутрішні дані бібліотеки, а остання очищає ці дані, для коректного завершення програми. Обидві ці функції бажано викликати тільки один раз у програмі (під програмою тут розуміється код, який розділяє один адресний простір). Тобто програма окрім функції main і підключень необхідних заголовкових файлів, буде містити ще два виклики функцій:
#include <curl/curl.h>
#include <iostream>
using namespace std ;
int main (int argc, char** argv)
{
if (curl_global_init (CURL_GLOBAL_ALL)!=0)
{
cout << "can`t init libcurl\n" ;
return 0 ;
}
curl_global_cleanup () ;
return 0 ;
}
Тепер, перед тим, як розпочати завантаження Інтернет-контенту необхідно створити спеціальний дескриптор бібліотеки, який має тип “CURL” (тобто вказівник на структуру). Він створюється наступним кодом.
CURL* handl = curl_easy_init () ;
Безпосередньо робота з бібліотекою складається з таких етапів:
- Встановлення основних параметрів за допомогою функції curl_easy_setopt();
- Запит на виконання операції за допомогою виклику функції curl_easy_perform();
- Виклик функції очищення дескриптора curl_easy_cleanup();
І найпростіша програма, яка завантажує сторінку “google.com.ua” може виглядати наступним чином:
#include <curl/curl.h>
#include <iostream>
using namespace std ;
/* функція входу в програму */
int main (int argc, char** argv)
{
/* ініціалізовуємо бібліотеку*/
if (curl_global_init (CURL_GLOBAL_ALL)!=0)
{
/* якщо не вдалося ініціалізувати
** бібліотеку - перериваємо роботу */
cout << "can`t init libcurl\n" ;
return 0 ;
}
/* створюємо дескриптор завдань libcurl */
CURL* handl = curl_easy_init () ;
/* перевіряємо валідність вказівника */
if (handl)
{
/* якщо все добре - виконуємо завантаження */
/* встановлюємо URL, контент якого ми бажаємо завантажити */
curl_easy_setopt (handl, CURLOPT_URL, "http://google.com.ua") ;
/* виконуємо завантаження */
CURLcode ret = curl_easy_perform (handl) ;
/* очищуємо дескриптор */
curl_easy_cleanup(handl) ;
}
else
{
/* якщо не вдалося створити дескриптор -
** вивести повідомлення про помилку */
cout << "fail to create curl object!\n" ;
return 0 ;
}
/* очищаємо бібліотеку */
curl_global_cleanup () ;
/* вихід з програми */
return 0 ;
}
Після виконання даної програми в вікні терміналу, Ви можете побачити наступне:
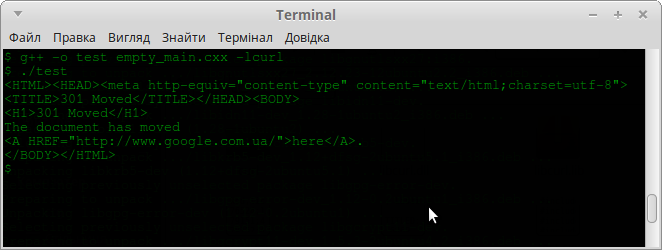 Ви також можете змінити посилання з “http://google.com.ua” на будь-який інший URL. Але завантажений вміст завжди буде виводитись у вікно терміналу. Це відбувається завдяки стандартному обробнику подій бібліотеки libcurl. Якщо Ви бажаєте змінити дану поведінку, необхідно встановити інший обробник події зчитування вмісту за допомогою функції curl_easy_setopt. Їй необхідно передати дескриптор в якості першого параметра, значення CURLOPT_WRITEFUNCTION другим параметром, а третім параметром — вказівник на функцію обробки події, яка повинна бути оголошена наступним чином:
Ви також можете змінити посилання з “http://google.com.ua” на будь-який інший URL. Але завантажений вміст завжди буде виводитись у вікно терміналу. Це відбувається завдяки стандартному обробнику подій бібліотеки libcurl. Якщо Ви бажаєте змінити дану поведінку, необхідно встановити інший обробник події зчитування вмісту за допомогою функції curl_easy_setopt. Їй необхідно передати дескриптор в якості першого параметра, значення CURLOPT_WRITEFUNCTION другим параметром, а третім параметром — вказівник на функцію обробки події, яка повинна бути оголошена наступним чином:
size_t write_callback (char *ptr, size_t size, size_t nmemb, void *userdata) ;
Зверніть увагу, що дана функція повинна повертати значення розміру оброблених даних таке ж, яке передала їй сама бібліотека. Якщо дана умова не справджується, тобто значення, яке повернула дана функція відрізняється від значення переданих даних — бібліотека перериває подальше зчитування і повертає помилку. Щоб уникнути дану проблему слід повертати значення (size*nmemb), якщо, звісно, Ви не бажаєте перервати подальше завантаження.
Проста програма з використанням власного обробника зчитування даних, може виглядати наступним чином:
#include <curl/curl.h>
#include <iostream>
using namespace std ;
/* вектор, в якому будуть міститись усі отримані дані*/
vector <char> all_data ;
/* обробик події зчитування вмісту */
size_t write_callback (char *ptr, size_t size, size_t nmemb, void *userdata)
{
/* копіюємо дані, які містяться в ptr у вектор */
for (unsigned int iter=0; iter<((size*nmemb)); ++iter)
{ all_data.push_back (ptr[iter]) ; }
/* повертаємо правильне значення !!! */
return size*nmemb ;
}
/* функція входу в програму */
int main (int argc, char** argv)
{
/* ініціалізовуємо бібліотеку*/
if (curl_global_init (CURL_GLOBAL_ALL)!=0)
{
/* якщо не вдалося ініціалізувати
** бібліотеку - перериваємо роботу */
cout << "can`t init libcurl\n" ;
return 0 ;
}
/* створюємо дескриптор завдань libcurl */
CURL* handl = curl_easy_init () ;
/* перевіряємо валідність вказівника */
if (handl)
{
/* якщо все добре - виконуємо завантаження */
/* встановлюємо URL, контент якого ми бажаємо завантажити */
curl_easy_setopt (handl, CURLOPT_URL, "http://google.com.ua") ;
/* встановлюємо обробник подій */
curl_easy_setopt (handl, CURLOPT_WRITEFUNCTION, write_callback) ;
/* виконуємо завантаження */
CURLcode ret = curl_easy_perform (handl) ;
/* очищуємо дескриптор */
curl_easy_cleanup(handl) ;
}
else
{
/* якщо не вдалося створити дескриптор -
** вивести повідомлення про помилку */
cout << "fail to create curl object!\n" ;
return 0 ;
}
/* якщо все пройшло добре - в даній точці програми ми отримали
** вектор заповнений даними, які містяться за адресою URL Інтернету,
** і ми можемо виконати з ними будь-які необхідні операції */
/* очищаємо бібліотеку */
curl_global_cleanup () ;
/* вихід з програми */
return 0 ;
}
Після виконання даної програми, Ви не побачите у вікні ніяких даних, оскільки весь завантажений вміст тепер міститься в векторі "all_data". Ви можете записати вміст вектора у файл, або ж зробити певний аналіз чи щось інше. Тільки будьте уважні - вміст за адресою URL може мати не текстовий формат, наприклад, виконуваний файл.
Резюме
В даній статті, Я показав як легко можна завантажувати вміст з мережі Інтернет, використовуючи бібліотеку libcurl. Для розширеної документації по можливостям і API бібліотеки зверніться до сайту її розробників.